
Vocabulaire de l'IA
Dans cette page, tu découvriras le vocabulaire lié au machine learning organisé par grandes thématiques:
Notions générales
Réseau de neurone
Un réseau de neurone est un approximateur universel de fonction, cela signifie qu’il peut apprendre le lien entre une entrée et une sortie quel qu’il soit à partir du moment où il existe une relation logique entre ces valeurs.
Entrée – Input
C’est les données que l’on va fournir à notre réseau de neurones à partir desquelles on lui demande de faire quelque chose.
Sortie – Output
C’est le résultat de notre réseau de neurone à partir d’une entrée spécifique.
Couches – Layer
Une couche est un ensemble de neurones que l’on peut rattacher à une ou plusieurs couches en entrée et une ou plusieurs couches en sorties
On parle souvent de couches intermédiaires pour parler de toutes les couches entre la couche d’entrée et la couche de sortie, on parle également de couche cachée ou hidden layer.
L’existence de plusieurs couches cachées est ce qui caractérise le Deep Learning, l’apprentissage profond, sur plusieurs couches.
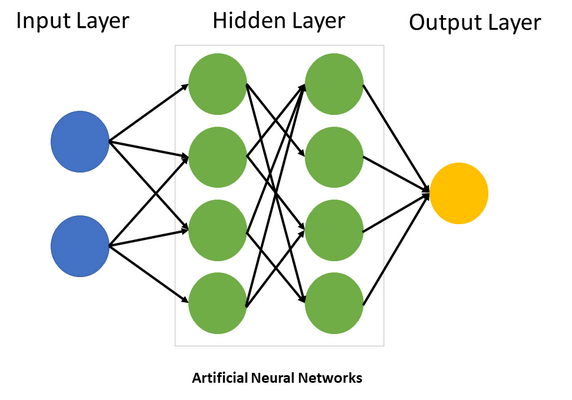
Fonctionnement d’un neurone
Pour chacune des entrées le neurone a un poids rattaché qui permet de régler l’importance de cette entrée pour le neurone. Le noyau du neurone fait la somme de toutes ces entrées. On applique un biais à cette somme qui retransmet cette somme de manière plus ou moins forte.
Enfin on peut ajouter une fonction d’activation.
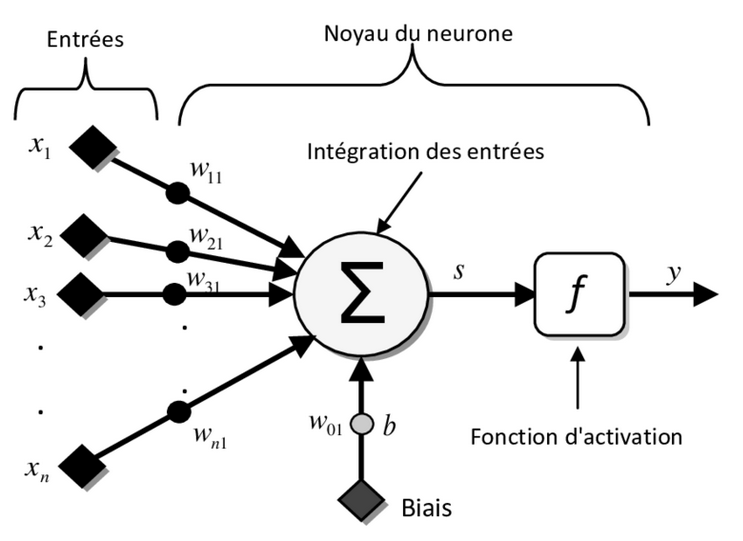
Fonction d’activation
Cette fonction sert à modifier la sortie de manière non linéaire en appliquant une fonction à cette sortie.
Par exemple, la fonction RELU transforme les valeurs négatives en 0, les sigmoides s’assure que toutes les valeurs soient entre -1 et 1, etc…
Dataset vs Database
Un dataset est la partie utile de cette base de donnée, celle qui va servir à entrainer notre réseau de neurones une fois préparé. Dans notre dataset on a les entrées (X) et les sorties (Y) qui serviront à notre entrainement.
Les grandes étapes d’un projet de machine learning
Préparer son dataset
X_train
C’est le nom de variable que l’on donne aux données d’apprentissage qui servent d’entrée à notre réseau de neurone.
C’est grâce à ces données qu’il va s’entrainer.
Y_train
C’est le nom de variable que l’on donne aux données d’apprentissage que l’on attend en sortie de notre réseau de neurones. C’est ce qu’on attend qu’il prédise lors de l’entrainement.
X_test
C’est le nom de variable que l’on donne aux données de test qui servent d’entrée à notre réseau de neurones.
On utilise ces données pour évaluer la capacité du réseau à généraliser sur de nouvelles données.
Y_test
C’est le nom de variable que l’on donne aux données de test que l’on attend en sortie de notre réseau de neurones.
Size vs Shape
Créer son modèle – les différentes couches
Sequential
input_shape
L’input shape est la forme de nos entrées.
Généralement on ajoute ce paramètre à la première couche de notre réseau de neurone pour spécifier la forme et s’assurer que les données aient la bonne forme.
activation
Dense
Une couche Dense est une couche dont tous les neurones ont pour entrée toutes les sorties de la couche précédentes et dont les sorties sont reliées à toutes les entrées de la couche suivante. On parle également de couche pleinement connectées – fully connected, pour exprimer que tous ces neurones sont connectés.
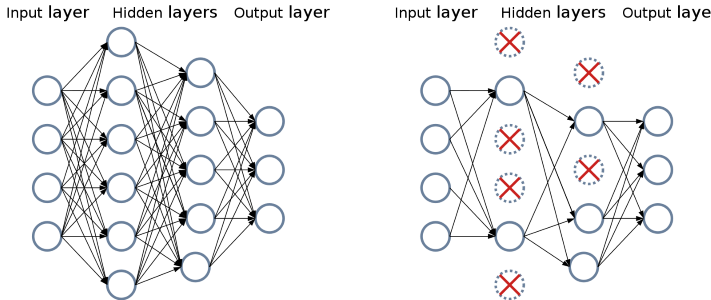
Dropout
Le dropout est un paramètre qui permet de couper une partie des connexions entre deux couches.
Cela permet d’endormir une partie du réseau à chaque apprentissage pour forcer la multiplication des chemins d’apprentissage afin de pouvoir généraliser.
Entraîner son modèle
compile
- l’optimizer : qui permet de gérer l’apprentissage du réseau de neurones et comment il arrive à corriger ses erreurs, ce implémente un outil mathématique, la descente de gradient. Généralement nous utilisons Adam
- la loss permet de calculer l’erreur du réseau de neurone, c’est à dire à quel point il y a un écart entre la sortie attendue et la sortie obtenue. Selon le type de problème que l’on cherche à résoudre on aura des calculs de loss différents. Par exemple :
- categorical_crossentropy pour des projets de classification
- binary_crossentropy pour une réponse binaire (oui/non avec un seul neurone en sortie)
- le metrics permettent d’ajouter d’autres éléments à afficher pendant l’apprentissage pour visualiser l’apprentissage. Généralement nous ajoutons l’accuracy qui permet d’afficher est-ce que le réseau à la bonne réponse
fit
Le fit est l’étape d’entrainement du réseau de neurones.
On peut faire plusieurs fit différents sur des données différentes avec plus ou moins d’épochs et relancer l’entrainement tout en gardant l’état préalable du réseau.
Pour l’entrainement on doit préciser :
- les données d’entrainement : les entrées et les sorties (X_train et Y_train)
- le batch_size : l’entrainement ne se fait pas sur l’intégralité des données en une fois, on découpe ces données en plusieurs lots. La batch_size définit la taille de se lot. L’intérêt est que le réseau prends l’intégralité d’un lot et essaye de se corriger sur toutes les données de ce lot afin d’avoir le meilleur réglage possible.
- l’epochs : définit le nombre de passage sur l’intégralité des données, combien de fois le réseau de neurones s’entraine sur toutes ces données.
- les validation_data : sont les données qui seront utilisées pour tester le réseau (X_train et Y_train). Pendant ce test, le réseau n’apprends plus, il teste juste ses réglages actuels sur des données qu’il ne connait pas.
Analyser l’apprentissage – lire le fit

loss vs accuracy
val_loss VS loss & val_acc VS accuracy
La val_acc et la val_loss sont les valeurs d’accuracy et de loss mais pour les données de validation. Cela permet de comparer les valeurs d’apprentissage et de test.
Overfiting
L‘overfiting est un sur apprentisage du réseau de neurones.
Cela signifie que le réseau de neurones n’est pas capable de généraliser, voir apprends par cœur. Cela se carractérise par une accuracy très forte et une loss très faible, ce qui laisserais croire que le réseau apprends bien, mais de l’autre côté on a une val_accuracy bien plus faible et une val_loss assez forte.

Underfiting
L’underfiting est un sous apprentissage du réseau.
Cela signifie que le réseau de neurones n’arrive pas à apprendre, quelque soit le nombre d’épochs, on garde une loss/val_loss forte et une accuracy/val_acc faible qui n’évolue pas.
