
Défis pandas météo
Sur cette page tu trouveras des défis pour redécouvrir pandas et lancer un entrainement avec un MLP sur un fichier csv.
Pour ces défis nous allons nous intéresser aux données météorologiques sur une année à Paris
Tu peux récupérer les données depuis ce lien.
Les défis sont organisés en plusieurs parties :
Pour bien réussir ces défis, tu auras besoin de ces fiches ressources :
Défis : Visualisation des données
Défi 0 : Récupération des données
Rends toi sur le site info climat qui recense et partage les données météos et télécharge les données sur le mois écoulé.
Importe le document CSV dans ton fichier google colab et créé une variable « fichier » qui contient le chemin d’accès au document.
Cette variable permettra de changer facilement le fichier au besoin.
Si le fichier est long à charger, tu peux récupérer les données complètes de 2023 à cette adresse et faire un !wget pour le charger directement sur colab : https://lp-magicmakers.fr/wp-content/uploads/2024/01/data_meteo_2023.csv
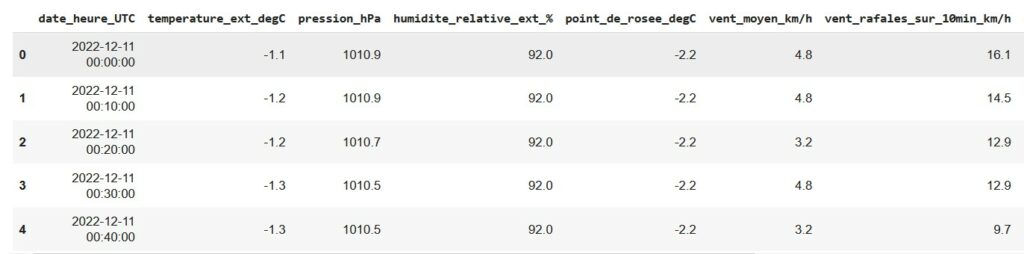
Défi 1 : Affiche les 5 premières lignes du fichier CSV et 5 lignes au hasard
Ouvre le fichier csv avec un dataframe panda et affiche les 5 premières lignes, puis 5 lignes au hasard.
Si tu n’arrives pas à voir les colonnes séparément, assure toi de spécifier le bon séparateur.
Voici un aperçu du résultat attendu !
Défi 2 : Shape et info() sur les colonnes
Affiche la forme du dataset pour obtenir le nombre de colonnes et le nombre de lignes qu’il contient avec data.shape
Affiche également le nom de toutes les colonnes et le type des valeurs contenues dans chaque colonne avec la fonction info().
Selon toi à quoi correspond chacune de ces valeurs ?

Défi 3 : Données statistiques sur la température le vent et la pluie

Défi 4 : Des jours et des heures
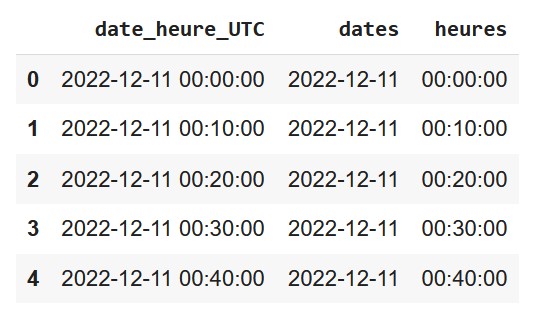
Actuellement nos dates et nos heures sont contenues dans une seule colonne : ‘date_heure_UTC’
Afin de pouvoir trier les données par date, ou par heures, on va créer deux colonnes différentes dates et heures pour stocker ces informations.
Pour cela on va utiliser les fonctions et variables suivantes :
- pd.to_datetime(data_à_transformer) qui transforme les données de type chaines de caractères en objet datetime
- dt.date qui récupère la date d’un objet datetime
- dt.time qui récupère le temps d’un objet datetime
Pour créer une nouvelle colonne dans un dataframe pandas, ça marche comme avec un dictionnaire, il suffit d’indiquer le nom de la colonne à créer entre crochets et lui affecter des valeurs.
Tu peux utiliser ce type de syntaxe en utilisant les bons noms de colonnes :
data['ma_nouvelle_colonne'] = pd.to_datetime(data['ma_colonne_initiale']).dt.date
Affiche les premières lignes des colonnes dates et heures pour vérifier que tout s’est bien passé.
En cas d’erreur, pense à bien recharger le dataset 😉
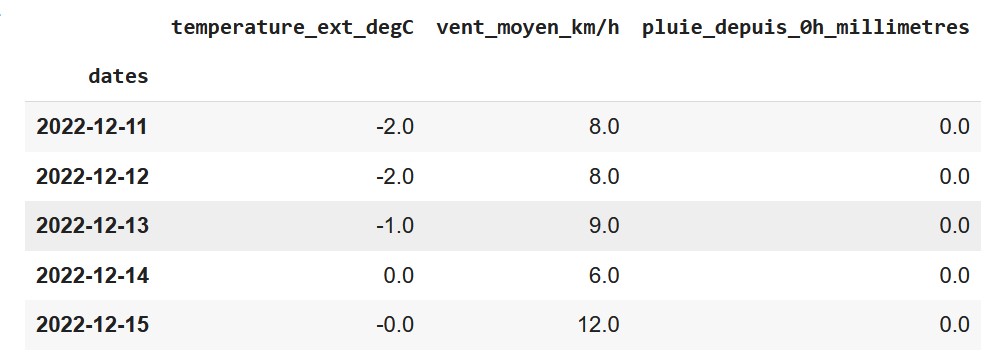
Défi 5 : Regroupons par date
A l’aide de la fonction groupby([‘colonne’]) regroupe les prévisions par jour et affiche les valeurs minimales, maximales et moyennes.
Défi 6 : Créons un nouveau tableau !
- temp_max, temp_min et temp_moy
- vent_max, vent_min et vent_moy
- pluie_mac, pluie_min et vent_moy
On peut utiliser la fonction rename() pour le faire. Tu peux également afficher le nom des colonnes avec l’attribut columns
Pense à visualiser quelques éléments de chaque tableau.
Tu peux remarquer que grâce à la fonction groupby, les index des lignes ne sont pas des nombres, mais les dates elles-mêmes. Cela va nous être utile pour fusionner ces tableaux.
Pour fusionner les trois tableaux on va utiliser la fonction join(). Pense à stocker ce nouveau tableau dans une variable data_jours et à l’afficher.
Voici le résultat attendu :
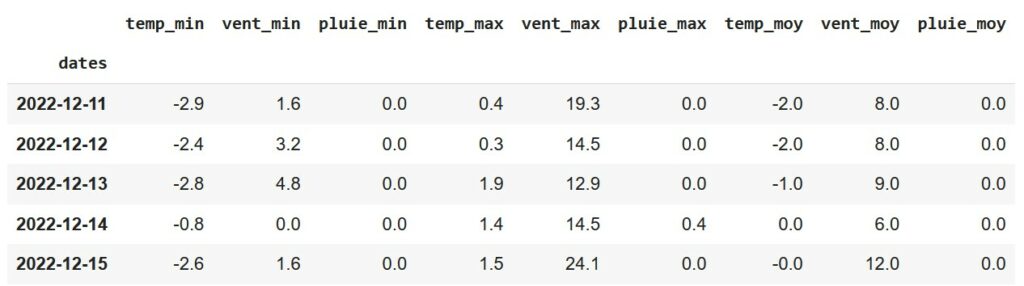
Défi 7 : Traçons les courbes
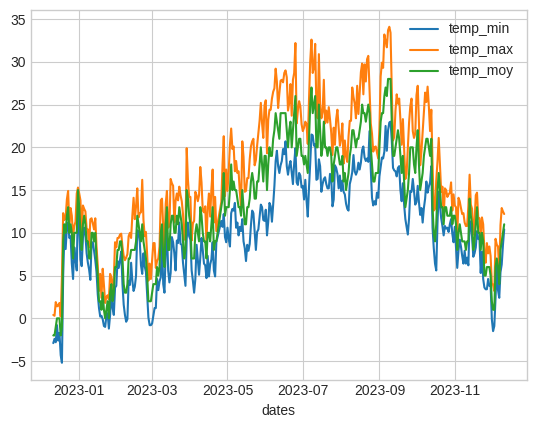
Souvent une bonne courbe vaut mieux que de longs tableaux pour l’oeil humain.
La fonction plot() permet de visualiser facilement les données.
- L’évolution de la température au fil du temps (min, max et moyenne sur un même graphe)
- L’évolution de la pluie au fil du temps (min, max et moyenne)
- L’évolution du vent au fil du temps (min, max et moyenne)
- L’évolution moyenne des températures, du vent et de la pluie au fil du temps
Défis bonus:
A l’aide des différentes notions vues jusque-là, du site ressources et de la cheatsheat pandas, essaye de trouver les informations suivantes :
- Quel est le jour où il a le plus plu cette année?
- Combien de pluie est tombée ce jour là?
- Quelle température moyenne faisait-il ce jour-là?
- Combien de jours y a t’il eu dans l’année sans aucune goutte de pluie?
- Y a t’il un lien entre les températures, les radiations solaires et le niveau d’UV? Pour répondre à cette question, trace la courbe de ces valeurs. Si les radiations sont trop élevées, tu peux les diviser par 100.
- Qu’en est-il de la chaleur, la pluie et l’évaporation? Attention l’évaporation est cumulée, pour bien pouvoir la comparer il faut faire la différence entre la pluie du jour et celle de la veille. Pour ça tu peux utiliser la fonction diff()
Défis : Préparation des données et entrainement simple
Défi 0 : Récupère et affiche une description du fichier d’entrainement
Tu peux trouver le fichier que l’on utilisera pour l’entrainement à cette adresse :
https://lp-magicmakers.fr/wp-content/uploads/2024/01/latmos_2018_2021_corr.csv
Récupère ce fichier, charge le comme un csv et affiche une description de ce fichier.
Défi 1 : Normaliser les valeurs entre -1 et 1
Pour que notre réseau s’entraine bien, on veut que nos valeurs soient comprises entre -1 et 1.
Pour cela on peut tout simplement diviser les températures par les températures maximales (en arrondissant au supérieur pour que ce soit plus simple)
Par contre dans certains cas, ça peut-être plus compliqué. Pour la pression par exemple, on voit que la pression moyenne est autour de 1014hPa et que le min est autour de 970, pour un max autour de 1042. Si on divise par 1042, nos informations vont être très tassées. On peut recentrer les valeurs autour de 0 pour avoir plus de diversités dans les valeurs. Pour cela on centre autour de la moyenne.
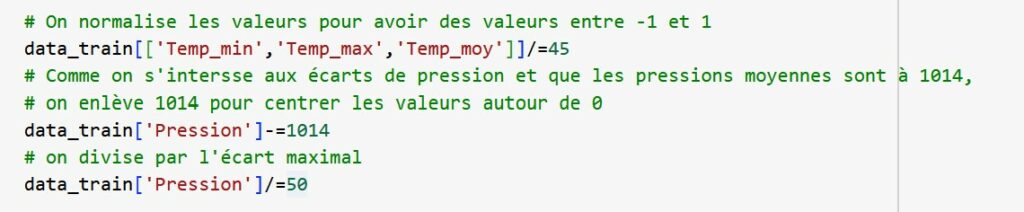
Défi 1 bis : Supprimons les valeurs vides et visualisons tout ça
Pour que notre réseau s’entraine bien nous allons également devoir supprimer les valeurs vides (NaN) avec la fonction dropna()
Affiche la description de ton nouveau data set pour t’assurer qu’il n’y ait aucune valeur inférieure à – 1 et supérieure à 1. Si ce n’est pas le cas, recommence le défi 1
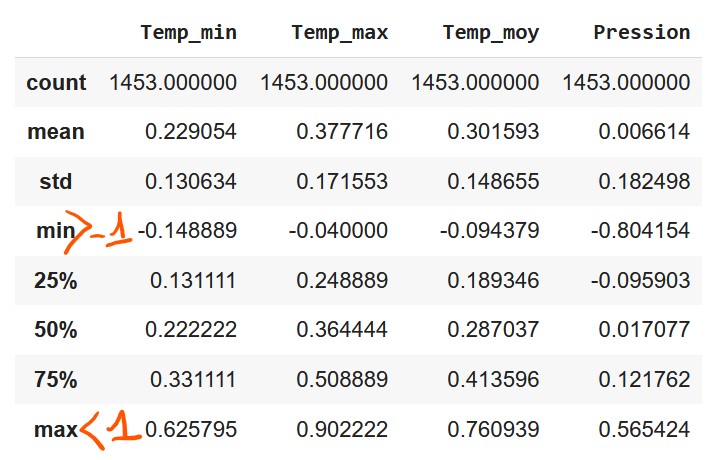
Défi 2 : X_train et Y_train, entrées et sorties
C’est le moment de créer nos entrées et nos sorties et d’afficher leur shape et leur head
- les entrées sont toutes les valeurs normalisées sur un jour, sauf le dernier jour (car on n’a pas les données du lendemain)
- les sorties sont les températures moyennes normalisées , sauf le premier jour (car on n’a pas les données de la veille)
Indices : Pour récupérer ces données, sélectionne les colonnes souhaitées et utilise les index avec la notation [a:b] pour prendre les valeurs uniquement entre a et b. La dernière valeur d’un tableau est accessible avec la valeur -1 et si tu ne mets rien avant les : ça prend tout ce qu’il y a avant, et inversement s’il n’y a rien après, ça va jusqu’à la fin.
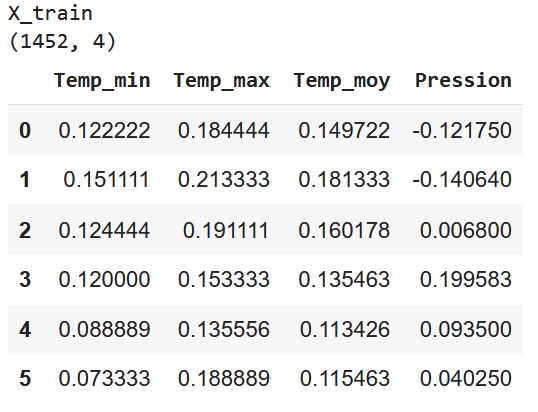
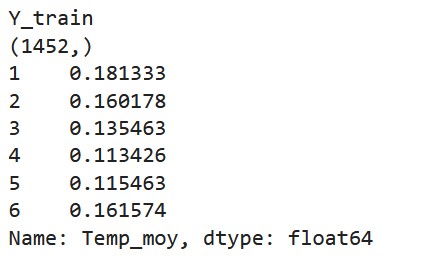
Tu peux avoir plus de colones et une shape différente si tu as gardé plus d’informations dans ton dataframe comme l’humidité ou le volume de pluie
Défi 3 : asarray, split et valeurs de test
Transforme tes dataframes en tableaux numpy avec la fonction np.asarray().
Puis utilise la fonction train_test_split() pour créer tes X_test et Y_test
Voici les imports dont tu auras besoin :
from sklearn.model_selection import train_test_split
import numpy as np
Pense à bien afficher les shape des X_train,Y_train,X_test,Y_test pour t’assurer que tout est ok
Défi 4 : Entrainement
Nous allons utiliser un modèle tout simple avec une seule couche Dense.
Comme notre problème n’est pas un problème de catégorisation, nous allons utiliser des fonctions d’activation et une loss un peu différente. Et cette fois encore l’accuracy ne sera pas une mesure très pertinente.
Voici le modèle que tu peux utiliser. Lance l’entrainement du modèle.
Imports
from keras.models import Sequential
from keras.layers import Dense
Code du modèle
# Un modèle très simple suffit avec uniquement la couche d'entrée, une couche intermédiaire et la couche de sortie
model = Sequential()
model.add(Dense(128, activation='relu',input_shape=(4,)))
# On ne cherche pas à faire de la catégorisation, mais à avoir vraiment une valeur entre - 1 et 1,
# donc on utilise tanh
model.add(Dense(1,activation="tanh"))
model.summary()
Compile
Pour le compile, on utilise une autre loss, car ce n’est pas un problème de catégorisation on s’intéresse donc à l’erreur moyenne
model.compile(optimizer="Adam",loss='mean_squared_error')
Fit
model.fit(X_train,Y_train,epochs=5,batch_size=16,validation_data=[X_test,Y_test])
Défi 5 : Prédiction et visualisation des résultats
Pour la prédiction nous allons essayer de prédire toutes les températures de 2022 à l’aide de ce fichier :
https://lp-magicmakers.fr/wp-content/uploads/2024/01/latmos_2022_day_corr.csv
- Commence par l’ouvrir et afficher une description (cf défi 0)
- Normalise les données et visualise la normalisation pour vérifier que tout est ok (cf défi 1 et 1bis)
Attention : garde la même méthode de normalisation que pour les valeurs d’entrainement sinon tes valeurs n’auront plus le même sens. Si tu te retrouves avec des valeurs qui ne sont pas dans [-1,1], utilise la fonction data.clip() pour les contraindre. - Lance la prédiction avec ton modèle et stocke les résultats dans une variable
- Sur une courbe, affiche les températures originales sur l’année et les prédictions effectuées sur l’année.
Aide toi des exemples de courbes tracés avec matplotlib
Défis bonus: D’autres apprentissages
Une fois que tu as réussi à entrainer l’IA et à visualiser l’évolution des températures sur l’année, tu peux te lancer dans l’exploration de l’apprentissage et tester les entrainements suivants :
- Est-ce que l’humidité et/ou le volume de pluie ont un impact sur la prévision si on les ajoute à nos données d’entrainement?
- Est-ce que si l’on supprime la pression on a d’aussi bons résultats?
- Est-ce qu’il est possible de prédire les températures minimales et maximales aussi?
- Qu’en est-il de savoir s’il va pleuvoir demain?
Tu peux toi même tenter différents entrainement avec les données que tu souhaites utiliser.
Défis : Création de séquences temporelles et Réseaux de neurones récurrents
Défi 1 : Création des séquences d’entrainements
Afin de lancer un entrainement avec un LSTM, nous allons avoir besoin d’un autre format pour nos entrées : la suite des données météo sur les N derniers jours en entrée, et la température moyenne du jour suivant en sortie.
Commence par créer une variable pour fixer la longueur de ta séquence et la changer facilement tu peux l’appeler taille_seq
Crée également tes listes X_train et Y_train.
A l’aide de data.iterrows() boucle sur chaque ligne de ton dataframe pour créer les entrées et les sorties.
Tu peux repartir du data_train avec les données normalisées créés dans la partie précédente.
A chaque itération ajoute :
- à X_train : toutes les valeurs des colonnes allant de la ligne courante jusqu’à les taille_seq lignes suivantes
- à Y_train: la température moyenne contenu dans l’index courant+taill_seq
Utilise la variable index de la boucle pour calculer les indices du tableau que tu souhaites récupérer, pas la ligne directement.
Pense à transformer les valeurs que tu récupères en tableau numpy.
Défi 1 bis : Gestion d’erreur et vérifications des données
Si tu boucles est bien faite, le programme va planter car il ne va pas réussir à récupérer tout le tableau. Pour l’arrêter correctement tu peux faire une gestion d’exception avec try except.
Transforme ensuite tes X_train et Y_train en tableau numpy et affiche la shape. Vérifie qu’ils aient bien la même taille (c’est à dire la même première dimension).
Si ce n’est pas le cas, tu peux inverser la récupération des X et des Y (car l’élément qu’on ajoute à Y est plus loin que celui de X) ou alors commence par récupérer chaque élément x et y que tu souhaites ajouter dans une variable temporaire avant de l’ajouter à ta liste. L’exception sera alors déclenchée lors de la récupération et pas après l’ajout.
Vérifie également que l’élément inséré dans Y est bien l’élément suivant le dernier élément de X en affichant les taille_seq premiers éléments du data_train et Y_train[0] et X_train[0]
Pense aussi à faire un train_test_split pour avoir des données de test
Défi 2 : Entrainement
Nous allons utiliser un modèle tout simple avec une seule couche LSTM et une couche Dense pour la sortie.
Comme notre problème n’est pas un problème de catégorisation, nous allons utiliser des fonctions d’activation et une loss un peu différente. Et cette fois encore l’accuracy ne sera pas une mesure très pertinente.
Voici le modèle que tu peux utiliser. Lance l’entrainement du modèle.
Imports
from keras.models import Sequential
from keras.layers import Dense, LSTM
Code du modèle
# On crée un modèle séquentiel car les couches sont les unes à la suite des autres
modele = Sequential()
# L'input shape c'est la forme d'une entrée (ici c'est la taille de nos séquences et le nombre de colonnes dans notre dataframe)
modele.add(LSTM(64, input_shape=(seq_len,4)))
modele.add(Dense(1, activation="tanh"))
modele.summary()
Compile
Pour le compile, on utilise encore l’erreur moyenne comme loss, par contre on a un autre optimizer plus efficace pour les réseaux de neurones récurrents
modele.compile(optimizer="RMSprop",loss='mean_squared_error')
Fit
model.fit(X_train,Y_train,epochs=5,batch_size=16,validation_data=[X_test,Y_test])
Défi 3 : Prédiction et visualisation des résultats
Tu peux repartir du data_train normalisé précédemment
- Créé les différentes séquences d’entrainement et les résultats attendus pour pouvoir les visualiser (en suivant les étapes du défi 1 et 1 bis)
- Lance la prédiction avec ton modèle et stocke les résultats dans une variable
- Sur une courbe, affiche les températures originales sur l’année et les prédictions effectuées sur l’année.
Aide toi des exemples de courbes tracés avec matplotlib et de la shape de ta prédiction pour graduer l’axe X