Pour chacun des défis pense à bien utiliser des print,cv2_imshow ou des len pour visualiser ce que tu as créé.
Repérer un bon data set
Cats & Dogs
Rends toi sur la page kaggle de ce data-set et inspecte les images.
On souhaite faire un projet de classification de reconnaissance d’image entre chien et chat.
Ce data-set est-il adapté? Pourquoi?
Quels sont ces points forts et ces point faibles?
Walk or run
Rends toi sur ce data-set sur kaggle et inspecte les images.
On souhaite faire un projet de classification de reconnaissance d’image entre une personne entrain de courir et une personne entrain de marcher
Selon toi est-ce un bon data-set? Pourquoi?
Gentil ou méchant
Rends toi sur ce data-set sur kaggle et inspecte les images.
On souhaite faire un projet de classification de reconnaissance d’image entre un méchant ou un gentil dans l’univers de marvel
Selon toi est-ce un bon data-set? Pourquoi?
A toi de jouer maintenant
Cherche différents data-set d’image sur kaggle et demande toi si ce sont des bons ou mauvais data-set, qu’est ce que tu peux en tirer et est-ce qu’ils seraient intéressant à utiliser en projet libre.
Charger ses données
Nous allons travailler sur ce data-set contenant les signes représentants les lettres de l’alphabet en langage des signes.
Défi 1 : Charge toutes les images de la première lettre de ton prénom
Créé un tableau vide X_train
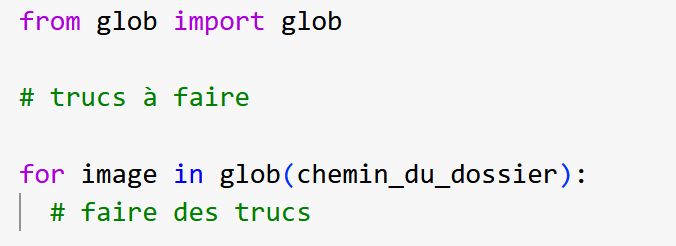
A l’aide de la fonction globouvre toutes les images et ajoute les à ton tableau (avec la fonction append).
Pense à ouvrir l’image avec cv2 avant de l’insérer dans le tableau
Défi 2 : Visualise le chargement
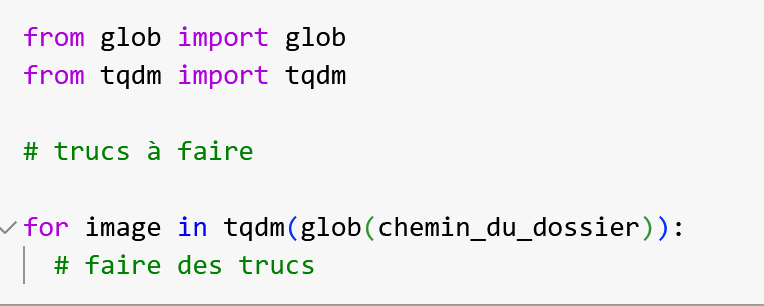
Quand on manipule beaucoup d’image le chargement peut être long. Pour visualiser la progression du chargement, on a une petite fonction super utile : tqdm
Utilise la fonction tqdm pour visualiser le chargement de tes images
Défi 3 : Créé tes labels
Pour notre apprentissage supervisé on a besoin de deux tableaux:
– X pour les entrées
– Y pour le label attendu en sortie
Créé maintenant un tableau Y_train dans lequel tu vas ajouter la lettre représentée sur l’image.
Défi 4 : L’ordinateur ne connaît que les nombres
Pour nos labels, on va préférer les représenter avec des nombres en commençant à 0.
Au lieu d’ajouter la lettre ajoute plutôt un 0 pour représenter cette lettre, et tu utiliseras 1,2,3,etc… pour les autres lettres que tu choisiras.
Créé aussi une zone de texte pour noter ce choix et pouvoir t’en souvenir facilement par la suite
Il est temps maintenant de passer à la préparation des données, mais toutes ces étapes seront à reproduire pour chacune des catégories utilisées.
Préparer ces données
Nous allons maintenant nous intéresser aux différentes étapes de préparation des données pour que l’on puisse créer une IA capable de reconnaître deux lettres différentes.
Défi 0 : 255 c’est trop grand
Pour que notre réseau fonctionne bien on veut réduire les valeurs de chacun des pixel à une valeur entre 0 et 1. Pour cela transforme les pixel en float et divise ton image par 255.
Intègre bien évidement cela à ta boucle pour préparer toutes tes images avant de les ajouter à X_train
Défi 1 : Toutes à la même taille
Bien que les auteurs de la base de données nous informent que les images sont toutes à la même taille (200×200), on va s’assurer que ce soit cas.
Redimensionne chacune de tes images avec la fonction cv2.resize(image,(h,l)) pour qu’elles soient en 100×100
Note : Il arrive que parfois nos données soit trop nombreuses et trop lourdes pour toutes les charger sur colab, en réduisant la taille on évite que ça arrive.
Défi 2 : Et la forme alors?
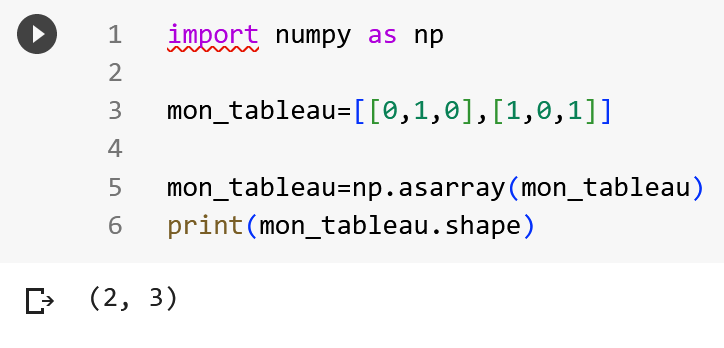
On veut maintenant visualiser la forme de nos données, on en aura besoin pour connaître notre input shape.
Pour cela on a besoin de la librairie numpy et de la fonction asarray pour transformer notre liste en un tableau numpy, puis on affiche la shape.
Note: ta shape doit être (3000,100,100,3) pour le X et (3000) pour le Y si ce n’est pas le cas tu as raté une étape ou rajouté une étape.
3000 : c’est le nombre d’image dans une catégorie
100 et 100 : c’est la largeur et la longueur de l’image
3 : c’est le nombre de couleur
Défi 3 : Et de deux !
Il est temps de prendre une deuxième lettre et de refaire toutes ces étapes !
Pense à bien changer le label de cette deuxième catégorie.
Les shapes doivent maintenant être (6000,100,100,3) en X et (6000) en Y
Défi 4 : Place aux probabilités
Dans tout problème de classification on récupére des tableaux de probabilités en sortie de notre réseau. Il faut donc transformer nos sorties en tableau de probabilités avec la fonction to_categorical.
from keras.utils import to_categorical
Défi 5 : On s’entraîne ?
La préparation semble bonne, mais quel est le meilleur moyen de vérifier tout ça? Voir si le réseau s’entraîne.
Récupère un réseau avec CNN que tu as déjà utilisé, ou celui-ci.
Pense à modifier l’input_shape et le nombres de catégories pour qu’il soit adapté à nos données puis lance un fit sur 1 epoch. Pas besoin d’en faire plus, on veut juste s’assurer que toutes nos étapes fonctionnent!
Défi 6 : Créons des données de test
Dans certains data set nous n’avons pas de données de test fournies séparément.
A l’aide de la fonction test_train_split, nous allons pouvoir découper nos X et Y en deux parties en gardant l’ordre et la correspondance entre les tableaux et de manière aléatoire.
Découpe ton X_train et ton Y_train en deux parties et affiche leur shape pour vérifier que tout s’est bien passé.