
CV2 avancé
Dans cette page tu trouveras des notions avancées sur l’utilisation de CV2 et comment augmenter ton nombre d’images
- Ouverture et changement de couleurs
- Détection de seuil
- Bien recadrer ses images et gérer leurs tailles
Ouverture et changement de couleurs
Dans cette partie nous allons voir comment ouvrir notre image en différents formats de couleur et comment modifier les couleurs
Ouvrir avec les bonnes couleurs
Pour ouvrir une image tu utilise la fonction cv2.imread(fichier, flag)
Le flag (drapeau) marque la manière dont il faut l’ouvrir. Voici les trois drapeaux possibles :
- cv2.IMREAD_COLOR : Ouvre l’image en couleur (RGB)
- cv2.IMREAD_GRAYSCALE : Ouvre l’image en niveau de gris
- cv2.IMREAD_UNCHANGED : Ouvre l’image dans le format dans lequel elle a été enregistrée, par exemple garde la transparence si elle existe (RGBA)
Changer les couleurs
Pour ouvrir une image tu utilise la fonction cv2.cvtColor(image,flag)
Le flag (drapeau) marque la manière dont il faut changer les couleurs. Il y en a de nombreux, voici la liste complète et quelques drapeaux possibles :
- cv2.COLOR_BGR2GRAY: transforme une image en couleur en une image en niveau de gris
- cv2.COLOR_GRAY2BGR : transforme une image en niveau de gris en une image en couleur
- cv2.COLOR_BGRA2BGR: enlève la transparence d’une image
Détection de seuil : Threshold
Pour certains projet de reconnaissance d’image il peut être intéressant de simplifier les informations que l’on voit sur l’image pour aider l’IA à apprendre. C’est ce qu’on fait sur le mnist : un chiffre manuscrit est un chiffre, peut importe la couleur, l’épaisseur etc.
La détection de seuil permet de limiter le nombre de couleur :
- On fixe un seuil (une valeur entre 0 et 255) :
- Si notre valeur est en dessous de ce seuil on remplace par la couleur A
- Sinon on remplace par la couleur B
Il existe différentes manières de faire de la détection de seuil et même des moyens de faire de la détection de seuil automatique. Nous ne rentrerons pas dans les détails mathématiques de ces fonctions mais allons voir comment les utiliser.
Tu trouveras toute la documentation sur les détections de seuil directement sur cette page
Détection simple
La fonction de détection simple est :
cv2.threshold( image, seuil, valeur_max,type_seuil).
Voici quelques exemples de types de seuils:
- cv2.THRESH_BINARY : ce qui est en dessous du seuil est mis à 0, le reste à max_value
- cv2.THRESH_BINARY_INV : c’est l’inverse, ce qui est en dessous du seuil est mis à max_value, le reste à 0
Tu en trouveras d’autre sur cette page
Détection automatique
La fonction de détection simple est :
cv2.adaptiveThreshold( image, valeur_max, methode_detection, type_seuil, taille_voisinage, constante ).
Les types de seuils sont les même que pour la détection simple.
Il existe deux méthodes de détection, réalisées avec des méthodes mathématiques différentes :
- cv.ADAPTIVE_THRESH_MEAN_C: calcule la moyenne sur le voisinage en enlevant la constante
- cv.ADAPTIVE_THRESH_GAUSSIAN_C: calcule une courbe gaussienne pour lisser sur le voisinage en enlevant la constante
Nous n’entrerons pas dans les détails mathématiques, mais la gaussienne à tendance à lisser le bruit et avoir une image plus nette, mais risque de perdre des détails.
Pour le voisinage, cela dépends de la taille de l’image, sur une image de 28×28, 10 pixels est un bon ordre de grandeur. La valeur du voisinage doit être impair : 1 pour le pixel lui même + n pixel à droite + n pixel à gauche, d’où la forme en 2n+1
Pour la constante il s’agit souvent de constantes positives, mais elles peuvent être nulles ou négatives. Elle a un effet sur le bruit et a un impact sur les pixels proches du seuil local.

Bien recadrer ses images et gérer leur tailles
Rappel
L’origine de cette matrice est située en haut à gauche.
On peut afficher la taille avec la fonction shape
print(image.shape) |
On récupérera un tuple de valeurs (hauteur, largeur), attention on récupère bien le Y avant X.
x = image.shape[1] |

Bien découper son image
Pour récupérer une partie de l’image c’est simple il suffit de préciser les positions de départs et d’arrivée dans chacune des dimensions. On parle de découpe, crop en anglais.
image_crop = image [depart_Y:arrivee_Y,depart_X:arrivee_X] |
Lors de la préparation de données on va vouloir avoir que toutes nos images aient la même taille.
On peut utiliser la fonction resize pour redimensionner, mais cela risque de déformer, mais on peut aussi simplement découper, ou faire un mélange des deux.
Pour découper il faut se poser la question : quelle est la partie de l’image qui est intéressante?
Et comme on en a plein et qu’on ne veut pas forcement les découper à la main on va essayer de garder un maximum de l’image.
L’algo de découpe
Voici une proposition d’algo pour maximiser la conservation de l’information.
- On détecte la taille de l’image la plus petite de notre dataset et on fixe une taille de référence qui est plus petite ou égale à cette taille
- Pour chaque image :
- on redimensionne l’image pour que la hauteur ou la largeur corresponde à la taille de référence (selon le format)
- on découpe ce qui déborde pour adapter la deuxième dimension à la taille de référence
Comment choisir dans quel sens redimensionner (étape 2.1)
Prends un temps pour essayer de ton côté et trouver des solutions par toi même, c’est plus satisfaisant si tu comprends tout seul!
X_ref et Y_ref correspondent à la taille de référence qu’on souhaite obtenir au final
X_image et Y_image correspondent à la taille initiale de l’image.
X_resize et Y_resize correspondent à la taille à laquelle on souhaite redimensionner l’image
Si tu es un peu bloqué voici une idée d’algo :
- On calcule les dimensions si X_image devient X_ref : X_resize = X_ref
- Calculons Y_resize à l’aide d’un produit en croix :
Y_resize = Y_image*X_ref/X_image- Si Y_resize est plus grand que Y_ref on redimensionne puis on rogne
- Sinon Y_image devient Y_ref
- Y_resize = Y_ref
- On calcule X_resize à l’aide d’un produit en croix : X_image*Y_ref/Y_image
- On redimensionne l’image avec X_resize et Y_resize
- On rogne l’image pour obtenir une image de taille (Y_ref,X_ref) à partir du centre de l’image
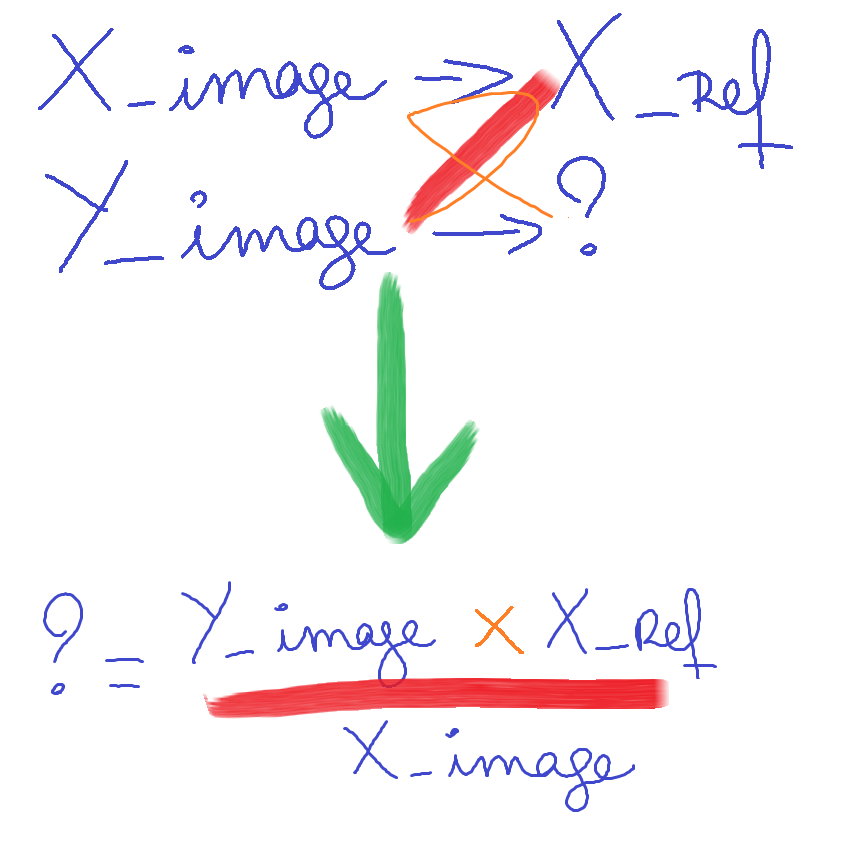
Ceci est une manière de faire, tu peu adapter et tester d’autres méthodes pour voir si tu arrives à de meilleurs résultats. Les maths ne sont qu’un outil mais c’est en analysant le format des images que tu pourra trouver le bon.
Attention quand on fait le resize, on mets d’abord le X puis le Y

Se simplifier la vie avec des images carrées
Une autre approche de cet algo peut-être de fixer une taille pour nos image de taille carrée, nos conditions deviennent un peu plus simple :
Il suffit de regarder si l’image et plus haute ou plus large et on redimensionne sur le plus petit coté.
Calculer le centre de l’image pour rogner à partir du centre
Premièrement on calcule le centre de notre image.
On sait que la largueur est X_resize et la hauteur Y_resize
Pour avoir le centre il suffit de diviser par deux:
X_centre = X_resize/2
Y_centre = Y_resize/2
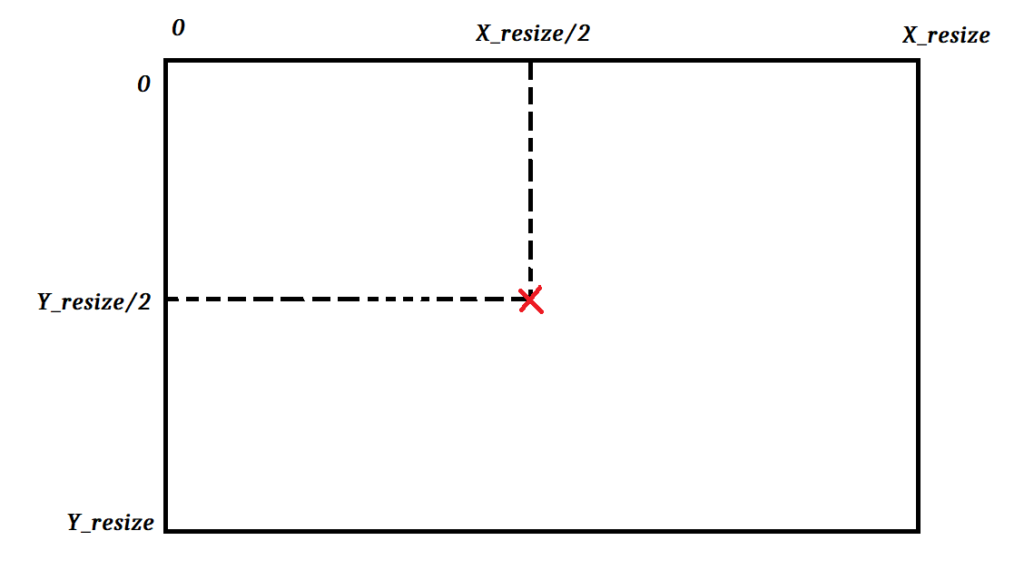
Ensuite la taille finale souhaitée est X_ref et Y_ref.
On souhaite récupérer la position de départ en X et en Y ainsi que la position d’arrivée.
Grâce au schéma ci-contre on voit que :
X_depart = X_centre – X_ref/2
X_arrivee = X_centre + X_ref/2
De même pour le Y.
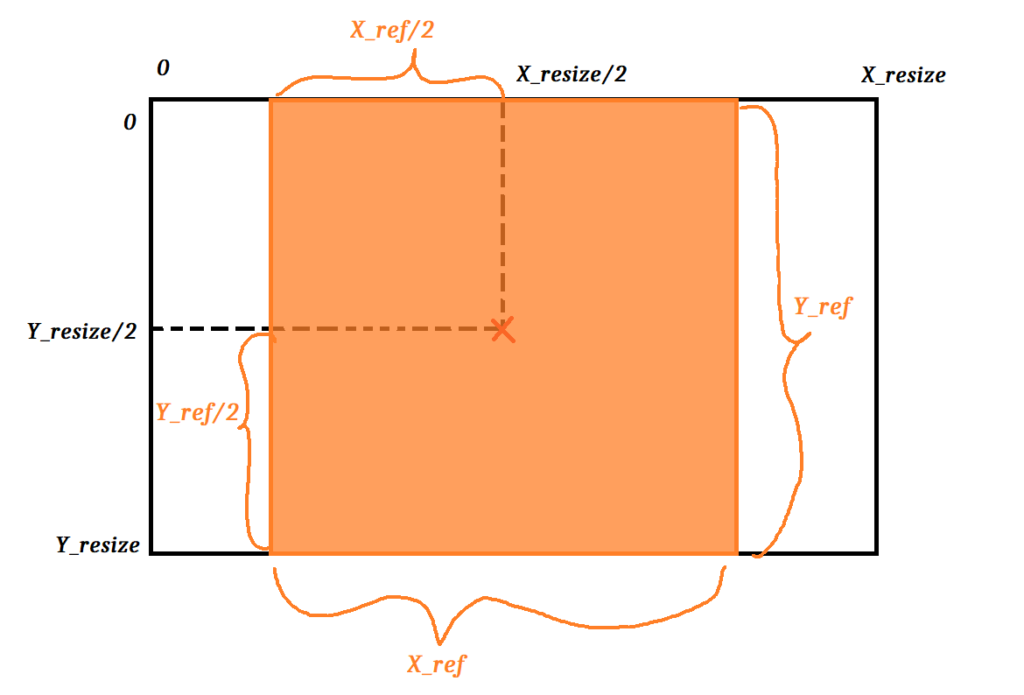
On peut aussi se simplifier la tâche si on sait que Y_ref==Y_resize.
Dans ce cas pas besoin de calcul :
Y_depart = 0 et Y_arrive = Y_resize
Attention : pour avoir des nombres entiers, il faut utiliser le symbole // cela peut aboutir avec les arrondis à un pixel de différence avec ta taille de référence, si c’est le cas, vous pouvez trouver une autre manière de calculer le crop ou faire un resize après le crop pour ajuster les pixels manquants