
Défis pandas
Sur cette page tu trouveras des défis pour prendre en main Pandas et découvrir le contenu de ton dataset.
- Toutes les infos sur le contenu du dataset sont disponibles sur sa page Kaggle.
- Tu peux également récupérer les données directement avec ce lien pour ton programme :
- https://lp-magicmakers.fr/wp-content/uploads/2023/09/student-mat.csv
Les défis sont organisés en 2 parties :
Défis de manipulation du dataset
Défi 1
Ouvre le fichier csv en t’aidant de la ressource pandas.
Pour cela :
- Télécharge le fichier csv à l’aide de !wget
- Importe pandas
- Ouvre le fichier csv (tu peux t’aider de cette partie)
Ensuite affiche le nom des colonnes qu’il contient et le type des données dans chacune de ces colonnes, grâce à la fonction info().

Défi 2
Affiche le nombre de lignes et le nombre de colonnes que contient notre dataset, avec la méthode shape
Défi 3
Lorsque l’on veut analyser les données d’un dataset, on peut souhaité ne pas voir de doublons pour une meilleure lecture.
Affiche les valeurs uniques contenues dans la colonne school avec la fonction unique().
Tu peux ajouter à ton print(), une chaine de caractère pour obtenir ce résultat.
- Pour se faire voici la syntaxe type :
- print(« chaine de caractère », fonction.unique )

Défi 4
Affiche les intitulés de chaque colonne, et leurs valeurs uniques contenues dans le dataset.
Pour cela :
- Boucle pour chaque index des colonnes du dataset grâce à la fonctiondata.columns
- Puis affiche pour chacun : le nom de l’index, concatène avec la string « = », puis la fonction unique sur chaque index du dataset

Défi 5
De nombreuses colonnes contiennent des valeurs textuelles. Les réseaux de neurones que nous utiliserons ont besoin que les données soient des valeurs numériques, afin de pouvoir manipuler ces données.
Remplace les valeurs textuelles des écoles en nombre à l’aide de la fonction loc() afin que :
- « GP » devienne « 0 »
- « MS » devienne « 1 »
– A l’aide de la fonction loc(), tu peux filtrer un élément d’une colonne et en changer sa valeur.
– N’oublie pas d’utiliser la fonction unique() pour afficher le résultat.
Défi 6
On peut avoir besoin de transformer des valeurs présentes dans plusieurs colonnes, de la même manière que vu au dessus.
Change toutes les valeurs yes et no du dataset de la façon suivante :
- « Yes » devienne « 1 »
- « No » devienne « 0 »
Pour cela :
- Stocke dans une variable colonnes-YN toutes les colonnes ayant des valeurs yes ou no en résultat
- Boucle pour chaque colonne dans la variable colonnes_YN
- Et utilise la fonction loc() pour changer chaque yes et no dans chaque colonne
Défis d’analyse des données
Défi 1
- Affiche les données statistiques des notes du 1er, 2e et 3e trimestre, à l’aide de la fonction describe()
- puis affiche les histogrammes de leurs répartitions à l’aide de la fonction plot.hist()
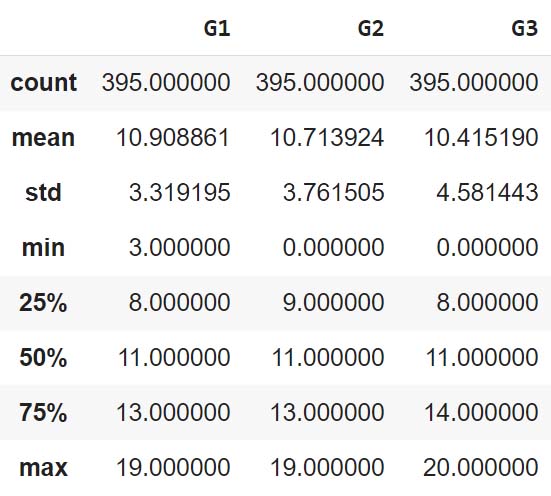
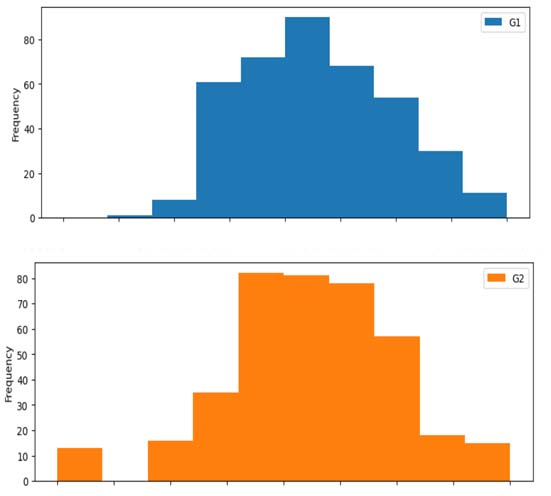
Quelles conclusions peut-on en tirer ?
Afin d’améliorer la lisibilité, tu peux utiliser le paramètre subplots = True afin d’afficher les histogrammes séparément.
Défi 2a
Dans le défi précédent, on a vu que le nombre d’élèves à avoir eu zéro de moyenne augmente avec le temps. C’est intrigant..
Affiche les résultats (G1,G2 et G3) des personnes ayant eu 0 au troisième trimestre, en affichant également les colonnes du 1er et 2e trimestre pour voir l’évolution de leurs notes générales tout au long de l’année.
Pour cela :
- Affiche les colonnes des 3 trimestres
- Puis joins la fonction query() pour filtrer uniquement les lignes ayant un 3e trimestre avec 0 de moyenne générale.
Que constate t’on ? Peut-on formuler une hypothèse qui justifie ce résultat ?
Défi 2b
Utilise à nouveau la fonction query() pour faire un nouveau dataset qui affiche toutes les lignes du 3e trimestre, qui ne sont pas égal à 0
Défi 3
Affiche les statistiques par trimestre selon les établissements à l’aide des fonction groupby() et describe().
Pour cela :
- Sélectionne la colonne école, 1er trimestre, 2e trimestre, et 3e trimestre
- Joins la fonction groupby() pour trier par école
- Et sors les stats en joignant aussi la fonction describe()
- Pour améliorer la lisibilité, tu peux utiliser l’argument percentiles = [ ] pour enlever les quartiles et la médiane.
- Est-ce que l’établissement à un impact fort sur la moyenne?
- Est-ce que c’est une donnée utile pour essayer de prédire les résultats scolaires?
- Est-ce que les valeurs qu’on a sur le minimum sont intéressantes ?
- N’y a t-il pas un moyen de les rendre plus intéressantes ?
- Ces résultats confortent-ils ou contredisent-ils ton avis sur l’utilité de ces données ?
- Vois-tu d’autres manières de regarder si ces données sont pertinentes ?
Défi 4
Affiche les résultats par trimestre selon l’âge à l’aide de groupby() et mean() en chainant les fonctions.
Pour cela:
- Utilise le même procédé qu’au défi 3 mais en sélectionnant l’âge
- Joins la fonction groupby()
- Puis la fonction mean()
- Est-ce que l’âge a un impact fort sur la moyenne ?
- Si oui, as-tu une idée du pourquoi ?
Affiche les mêmes résultats en utilisant la variable data_sans_0 qui stocke les résultats en enlevant tous les 0 de moyenne
- Qu’en penses tu ?
- Quelles hypothèses peut-on formuler à la lecture de ces résultats ?
Défi 5 :
Regardons maintenant l’équilibre des âges.
Affiche le nombre d’enfants de chaque âge qu’il y a dans notre dataset.
Tu peux utiliser pour cela la fonction value_counts().
Peut-on utiliser cette fonction pour vérifier les hypothèses précédentes quand aux 0 et à l’âge ?
Y a t’il certaines tranches d’âges pour lesquels nous n’avons pas assez de représentativité dans nos données, et trop peu d’infos ? Pourquoi à ton avis ?
Défi 6
A toi de jouer ! Continue de parcourir les données et de regarder si tu vois des corrélations entre certaines données ou des limites dans celles-ci. Prends le temps de noter tes analyses elles te seront utiles plus tard.